【AU3323】人工智能基础笔记
Basical AI notes
tags: notes AI Basic
CS188课程翻译笔记:
知乎|翻译1;知乎|翻译2;知乎|翻译3;知乎|翻译4;原版笔记资料CS188|Introduction to Artificial Intelligence.
1.search
1.1 Agent
在人工智能中,主要问题是建立一个rational(理性的)的agent,一个有特定目标或偏好并会针对这些目标试图执行一系列操作(action) 来得到最优解的实体(即一个理性决策者)环境和agent一起组成了一个世界
Reflex Agent
wiki|intelligent agent
感知代理(IA).根据当前感知(或者记忆)选择行动
可能拥有世界当前状态的记忆或模型
不考虑他们行为的未来后果,只是根据世界的当前状态而选择一个操作;何谓AI,感知其环境,自主采取行动以实现目标,并且可以通过学习或使用知识来提高其性能的任何东西;核心即目标导向行为视为智能的本质;
其Consider how the world is
Planning Agent
有一个世界模型并用这个模型来模拟执行不同的操作,能够确定操作的假想结果并依据此选择最佳操作,即实现预测
Consider how the world would be
have a model of how the world evolves in response to actions;其预测决策、行为的后果
1.2 State Spaces and Search Problems 状态空间和搜索问题
引入
首先给出概念定义:
- 搜索问题:给定agent的当前状态(state)(它在环境中的配置),我们如何尽可能最好地达到一个满足目标的新状态
- 状态空间state space:在给定世界中所有可能的状态
- 后继函数successor function:参数包含一个状态和一个操作,并计算执行该操作的代价(cost)和执行操作后世界的后继状态
- 起始状态start state:agent最初存在时当前世界的状态
- 目标测试函数goal test:一个函数,输入一个状态并决定它是否是一个目标状态(是否在目标集中)
- 世界状态world state:包含一个给定状态的所有信息
- 搜索状态search state:仅包含对计划(主要是为了空间效率)必要的信息
示例介绍:本课程使用吃豆人Pacman游戏做示例。吃豆人必须探索一个迷宫,吃掉所有的的小豆子并且不被游荡的恶灵吃掉。如果它吃了大豆子,它将在一段时间内无敌并且能吃掉恶灵赚取分
解决搜索问题的步骤:
- 考虑它的起始状态
- 用后继函数探索它的状态空间
- 反复计算不同状态的后继直到后继为目标状态
此时建立起计划路径连接起始与目标;在解决搜索过程中,由策略strategy来决定探索不同状态的顺序。
世界状态与搜索状态
示例搜索问题迷宫中只有吃豆人和豆子。在这种情况下我们能给出两种不同的搜索问题:路径规划和光盘行动(pathing and eat-all-dots)。路径规划需要找出从位置$(x_1,y_1)$到$(x_2,y_2)$的最佳方案,而光盘行动要求用尽可能短的时间吃掉迷宫中所有的豆子。
路径规划的状态包含的信息比光盘行动要少,因为在光盘行动中我们必须保存一大批布尔值用来表示在给定状态中每个豆子有没有被吃掉。一个世界状态还有可能包含更多的信息,比如吃豆人走过的总距离,或者吃豆人在它的当前位置(x,y)和豆子布尔值上到达过的所有地方这些潜在的编码信息。
简而言之,世界状态是整个世界中所有的信息,而搜索状态是对于一个搜索问题其所有需要输入的信息。
State Space Size 状态空间大小
状态空间大小可以用于估算搜索问题运行时间,其唯一计算方法:
如果在一个给定的世界里有n个变量分别有$x_1,x_2,x_3…$种不同的取值,那么状态的总数为$x_1x_2x_3x_4…$。
示例:我们用吃豆人来举例说明这个概念,吃豆人有120个位置,前进方向有4个,恶灵有两个,每个恶灵有12个可能位置,共有30个豆子,每个豆子有被吃或未被吃两种状态。则总状态空间大小$120\times4\times12^2\times2^{30}$
State Space Graphs and Search Trees 状态空间图和搜索树
上述示例用了四个部件来完整地定义了一个状态空间。
状态空间图(state space graph) 是由代表状态的结点以及从一个状态指向其后继的有向边构成的。这些边表示操作(action),而任何相关联的权重表示对应操作的代价。每个结点的状态都包括了上述4个元素。
注意: 状态空间图中每个状态只表示一次。
而对于搜索树,其对一个状态的出现次数没有限制。例如,空间图中的极长S → d → e → r → f → G,其在对应搜索树中反映为从根节点到叶子结点的一个道路。由于从一个状态到另一个状态通常会有多种方案,搜索树中状态会出现多次。简言之,搜索树中呈现的是搜索路径而不只是结点和结点间关系。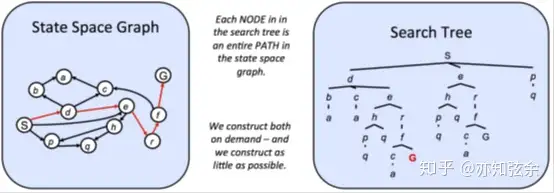
一般在搜索问题中,我们只保存即刻处理的状态,并用相应的后继函数根据需求来计算新的状态。
在树中,我们每次观察那几个非常小心地存储选择的节点,反复地用其后继来替换节点,直到我们到达一个目标状态。
下面将介绍一些方法来决定搜索树中迭代替换结点的顺序(即不同的策略strategy)。
Uninformed Search 未知搜索
首先介绍树搜索tree search:
通过移除一个与部分计划对应的节点(用给定的策略来选择)并用它所有的子节点代替它,我们不断地扩展(expand)我们的边缘(outer fringe)。用子节点代替边缘上的元素,相当于丢弃一个长度为n的计划并考虑所有源于它的长度为(n+1)的计划。我们继续这一操作,直到最终将目标从边缘移除为止。此时我们得出结论,与移除的目标状态相对应的部分计划其实就是从起始状态到目标状态的一条路径。
当我们不知道目标状态在搜索树中的的位置时,我们只能从属于未知搜索(uninformed search) 的技术中选择用于树搜索的策略。我们将依次介绍三种策略:深度优先搜索DFS、广度优先搜索BFS和一致代价搜索UCS,同时包括搜索策略的基本性质,包括完备性、最优性、分支因数h、最大深度m,最浅解深度s
DFS深度优先搜索
何为边缘,即是当前探索道路的两端(如果不算根的话,即是探索的“头”,多个道路可以有多个头)
- 描述:深度优先搜索DFS总是选择距离起始节点最深的边缘节点来进行扩展。DFS选择先访问邻接结点的邻接结点。
- 边缘表示:DFS在边缘将最深结点移除后让最深结点的孩子结点成为边缘,此时孩子结点的深度即是
原最深结点深度+1。即边缘中最近添加的对象总有最高优先级,使用栈(后进先出LIFO)来进行存储。 - 完备性:深度优先搜索并不具有完备性。如果在状态空间图中存在回路,这必然意味着相应搜索树的深度将是无限的(搜索树是空间图中极长道路组成的,空间图存在回路也就是没有极长道路了)。因此,存在这样一种可能性,即DFS老实地在无限大的搜索树中搜索最深的节点而不幸地陷入僵局,注定无法找到解。
- 最优性:深度优先搜索只是在搜索树中找到“最左边”的解,而没有考虑路径的代价,因此不是最优的。DFS先检索的是邻接表中的第一个邻接结点,可能有解但不一定是最优解
- 时间复杂度:在最坏情况下,深度优先搜索最终可能会搜遍整个搜索树。
- 空间复杂度:在最坏情况下,DFS在边缘上m个深度级别上都有b个节点。这是一个简单的结果,因为一旦某个父节点的b个子节点进入队列,DFS的本性在任意时间点都只允许研究任意一个子节点的一棵子树。即为$O(bm)$
BFS广度优先搜索
- 描述:宽度优先搜索总是选择距离起始节点最浅(近)的边缘节点来扩展。BFS选择先访问完全所有的邻接结点。
- 边缘表示:如果我们想在较深的节点之前访问较浅的节点,我们必须按照节点的插入顺序来访问它们。使用队列(先进先出FIFO)。
- 完备性:由于总是访问最浅边缘结点,而最浅结点深度一定是有限的(在存在解的前提下),故一定可以搜索下去而不会进入死循环,故完备。
- 最优性:BFS一般不是最优的,因为它在选择边缘上被替换的节点时不会考虑代价问题。在所有边的代价都相等的特殊情况下BFS可以保证是最优的,因为这会让BFS退化为一致代价搜索。
- 时间复杂度:遍历所有结点
- 空间复杂度:在最坏情况下,边缘所有节点都在对应最浅解的那一层。(全都要存,都要朝下面找)
Uniform Cost Search 一致代价搜索
- 描述:UCS总是选择距离起始节点代价(边权)最小的边缘节点来扩展。
- 边缘表示:UCS的边缘选择用优先堆(小顶堆),对于其中的结点v其权重即为从起始节点到v的路径代价,称之为v的后退代价backward cost。
- 完备性:如果存在一个目标状态v,它一定有从根到v的有限长度最短路径。故完备
- 最优性:当所有边权非负,UCS是最优的(按照路径代价递增的顺序搜索结点)
- 时间复杂度:
我们定义最优路径代价为$C^*$,状态空间图内两节点之间最小代价为$\varepsilon$。那么,我们得简单粗暴地遍历深度为从1到$\frac{C^*}{\varepsilon}$范围内的所有节点,导致运行时间为$O\left( b^{\frac{C^*}{\varepsilon}} \right)$。
注意:上述三种搜索策略本质都是树搜索,只是策略的不同。
Informed Search有信息搜索
UCS在完备性和最优性上很棒,但时间复杂度较高。如果我们对于我们应该搜索的方向有一定的了解,我们就能显著提高性能并更快地达到目标。这就是有信息搜索。即已知目标位置,可以估算到目标的距离。
Heuristics 启发式搜索
首先介绍启发式搜索的定义:
Heuristics are the driving force that allow estimation(估计) of distance to goal states - they(启发式搜索)’re functions that take in a state as input and output a corresponding estimate. 以一个状态作为输入,以相应的估计为输出。
启发式搜索这种函数是专门用来解决搜索问题的,
we usually want heuristic functions to be a lower bound on this remaining distance to the goal。我们希望启发式搜索可以获得剩余到目标距离的下限,因而启发式搜索通常处理relaxed problems。
示例:对于前面的路径规划问题,通用解决方法是曼哈顿距离法Manhattan Distance。定义两点间曼哈顿距离为:$Manhattan(x_1,y_1,x_2,y_2)=|x_1-x_2|+|y_1-y_2|$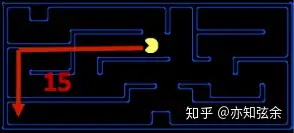
假想要到达左下角,它在计算了假设没有墙的情况下从吃豆人现在的位置到目标位置的距离。这个距离是松弛搜索问题中的精确(exact)距离,而相应的在实际的搜索问题中计算出的是估计(estimated)目标距离。从而实现了为agent建立“偏好拓展状态”的逻辑——做决策时总是使得估计结果更接近目标状态
With heuristics, it becomes very easy to implement logic in our agent that enables them to “prefer” expanding states that are estimated to be closer to goal states when deciding which action to perform.
下面讲到的两种搜索策略都是基于启发式搜索的原理。
Greedy Search贪婪搜索
- 描述:贪婪搜索总是选择有最小启发值(lowest heuristic value) 的节点来扩展,这些节点对应的是它认为最接近目标的状态。
Greedy search is a strategy for exploration that always selects the frontier node with the lowest heuristic value for expansion
- 边缘描述:贪婪搜索的操作和UCS相同,具有优先队列边缘表示。但贪婪搜索的堆中各结点用估计前进代价(estimated forward cost) 作为结点权值。
computed backward cost (the sum of edge weights in the path to the state)
- 完备性与最优性:对于一个目标状态,贪婪搜索无法保证能找到它,它也不是最优的,尤其是在选择了非常糟糕的启发函数的情况下。在不同场景中。它的行为通常是不可预测的,有可能一路直奔目标状态,也有可能像一个被错误引导的DFS一样并遍历所有的错误区域。但注意,贪婪搜索有着高搜索速度

A* search A*搜索
描述:A*搜索总是选择有最低估计总代价(lowest estimated total cost)的边缘节点来扩展
A* search is a strategy for exploration that always selects the frontier node with the lowest estimated total cost for expansion, where total cost is the entire cost from the start node to the goal node.其中lowest estimated total cost是指从起始节点到目标节点的全部代价
边缘表示:A*搜索也用一个优先队列来表示它的边缘。但A*搜索使用估计总代价estimated total value做结点权值,即
估计总代价=估计前进代价+后退代价完备性与最优性:在给定一个合适的启发函数(我们很快就能得到)时,A*搜索既是完备的又是最优的,兼备贪婪搜索的高搜索速度以及UCS的完备性和最优性。
Admissibility and Consistency 可纳性和一致性
接下来我们来花些时间讨论一下一个好的启发式是由什么构成的。下面定义:
- $g(n)$:UCS的总后退代价函数
- $h(n)$:贪婪搜索的启发值函数,即估计前进代价函数
- $f(n)$:A*搜索使用的估计总代价函数。有$f(n)=g(n)+h(n)$
首先要知道,对于A*搜索,其并不是总是保持其完备与最优。例如,启发函数$h(n)=1-g(n)$,则此时$f(n)=1$,退化为BFS问题(所有目标结点都在同一层级上),而BFS只有在所有边权值一致时才是最优。因此,使用A*搜索,其最优性有条件,称之为可纳性admissibility
The admissibility constraint(约束) states(表明) that the value estimated by an admissible heuristic is neither negative(负的) nor an overestimate(过估计).
可纳性约束
可纳性约束有数学表示:
$\forall{n,0}\leq{h(n)}\leq{h^*(n)}$
定理:对于一个给定的搜索问题,如果一个启发式函数h满足可纳性约束,使用含有h的A*树搜索能得到最优解
证明:假设两个可以到达的目标状态,最优目标A和次优目标B在一个给定的搜索问题的搜索树中。因为可以从初始状态到达A,A的某个祖先节点n(有可能是A本身)现在一定在边缘上。用以下三个陈述,我们可以断定n会在B之前被选来扩展